Unveiling The Efficiency Of HashMaps In Java: A Comprehensive Guide
Unveiling the Efficiency of HashMaps in Java: A Comprehensive Guide
Related Articles: Unveiling the Efficiency of HashMaps in Java: A Comprehensive Guide
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to Unveiling the Efficiency of HashMaps in Java: A Comprehensive Guide. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Unveiling the Efficiency of HashMaps in Java: A Comprehensive Guide
- 2 Introduction
- 3 Unveiling the Efficiency of HashMaps in Java: A Comprehensive Guide
- 3.1 Understanding the Essence of HashMaps
- 3.2 Delving Deeper into the Implementation
- 3.3 The Advantages of Employing HashMaps
- 3.4 Practical Applications of HashMaps
- 3.5 FAQs on HashMaps in Java
- 3.6 Tips for Effective HashMap Usage
- 3.7 Conclusion
- 4 Closure
Unveiling the Efficiency of HashMaps in Java: A Comprehensive Guide
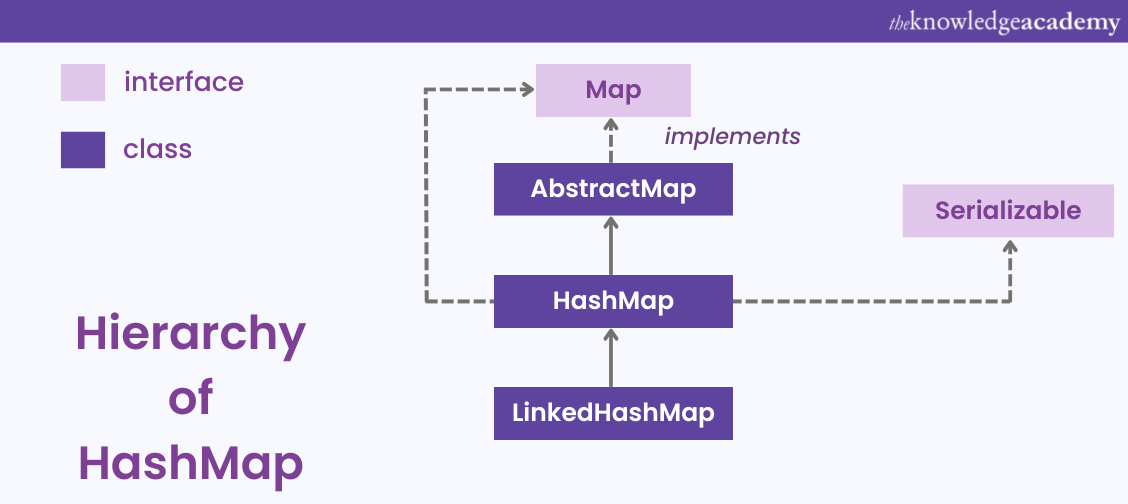
In the realm of Java programming, the HashMap stands as a cornerstone data structure, renowned for its exceptional performance in managing and retrieving key-value pairs. This article delves into the intricate workings of HashMaps, exploring their core functionalities, underlying principles, and practical applications.
Understanding the Essence of HashMaps
At its core, a HashMap in Java is a dynamic data structure that implements the Map interface. It utilizes a hashing function to map keys to their corresponding values, enabling rapid access to data. This hashing mechanism allows HashMaps to achieve significantly faster lookup operations compared to traditional linear data structures like arrays or linked lists.
Key Concepts:
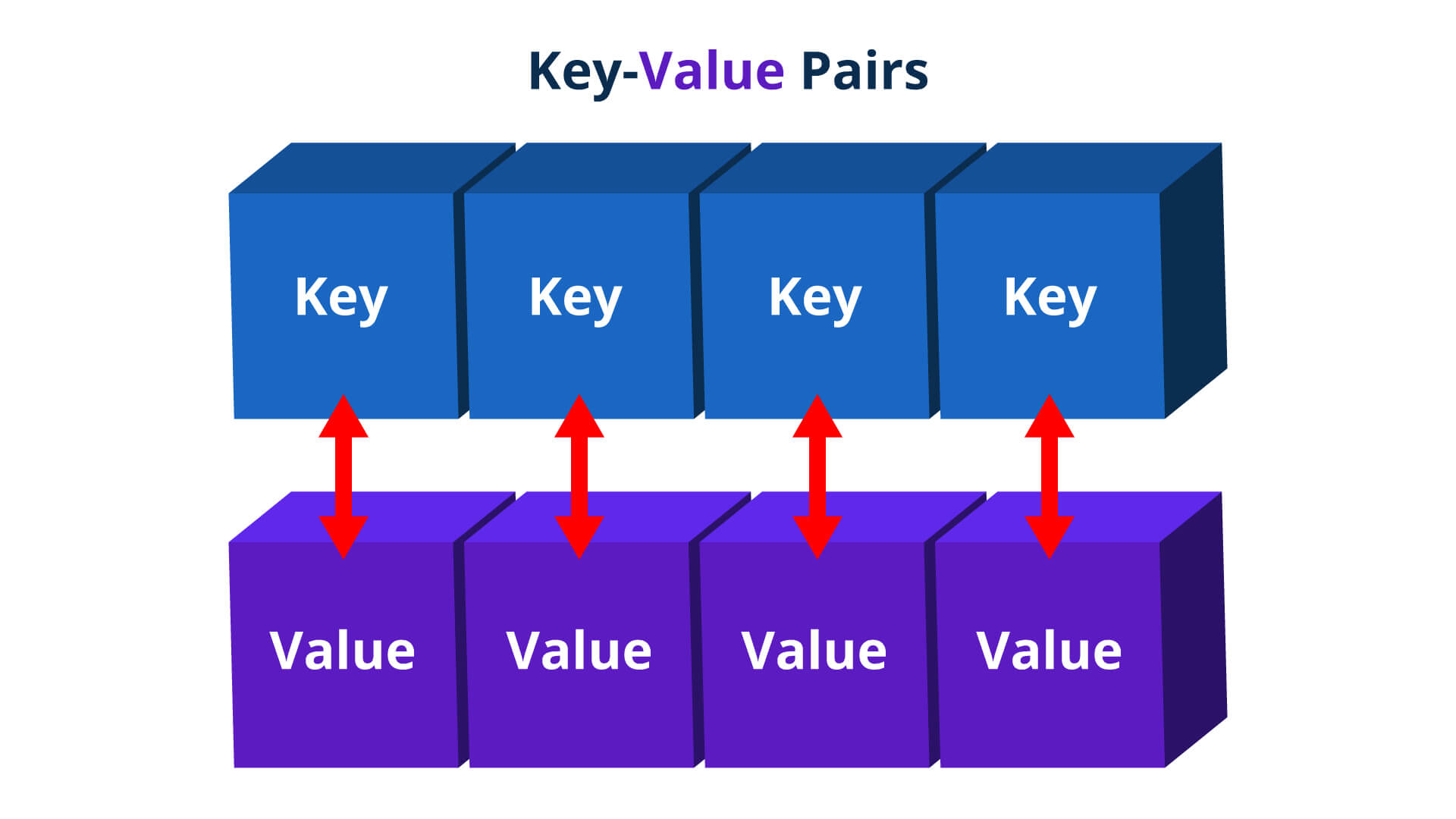
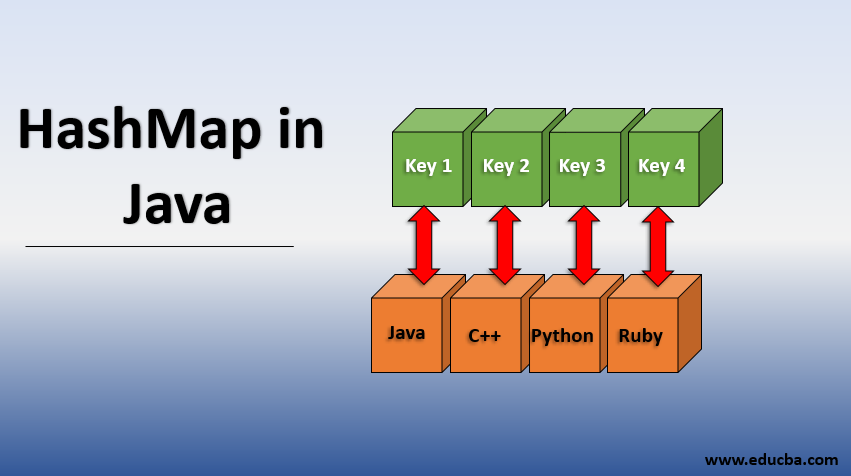
- Key-Value Pairs: HashMaps store data as key-value pairs. Each key must be unique, while the values associated with the keys can be of any type.
- Hashing Function: A hashing function takes a key as input and generates a unique integer value, known as a hash code. This hash code determines the location of the key-value pair within the HashMap.
- Collision Handling: Since different keys can potentially generate the same hash code, collision handling mechanisms are essential to ensure data integrity. HashMaps typically employ techniques like separate chaining or open addressing to resolve collisions.
Delving Deeper into the Implementation
HashMaps in Java are based on an array of linked lists. Each element in the array represents a bucket. When a key-value pair is added to the HashMap, the hashing function generates a hash code, which is then mapped to a specific bucket. The key-value pair is then stored in the corresponding linked list within that bucket.
Key Components:
- Array: The underlying array structure provides the foundation for efficient access and organization of data.
- Buckets: Each bucket in the array acts as a container for linked lists, enabling the storage of multiple key-value pairs with the same hash code.
- Linked Lists: Linked lists within buckets provide a mechanism for resolving collisions. When two keys generate the same hash code, their corresponding key-value pairs are stored in the same linked list.
The Advantages of Employing HashMaps
HashMaps offer several compelling advantages that make them an indispensable tool in Java development:
- Fast Lookup: The hashing mechanism enables near-constant time lookup operations, making HashMaps ideal for scenarios where rapid data retrieval is paramount.
- Dynamic Sizing: HashMaps automatically adjust their size as data is added or removed, eliminating the need for manual resizing and ensuring optimal performance.
- Flexibility: HashMaps support a wide range of data types, allowing developers to store and retrieve diverse information.
Practical Applications of HashMaps
HashMaps find widespread application across various programming domains, including:
- Caching: HashMaps excel at storing frequently accessed data, enabling rapid retrieval and reducing the need for expensive database queries.
- Dictionaries and Mappings: Their ability to associate keys with values makes HashMaps perfect for representing dictionaries and mappings, such as storing user profiles or language translations.
- Graph Algorithms: HashMaps facilitate the efficient representation and manipulation of graphs, enabling the implementation of algorithms like Dijkstra’s shortest path algorithm.
- Data Structures: HashMaps serve as the foundation for other complex data structures, such as HashSets and LinkedHashMaps.
FAQs on HashMaps in Java
Q: What is the time complexity of HashMap operations?
A: On average, HashMap operations like insertion, deletion, and retrieval have a time complexity of O(1), meaning they take constant time. However, in the worst-case scenario, when collisions occur, the time complexity can degrade to O(n), where n is the number of entries in the HashMap.
Q: How do I choose the initial capacity of a HashMap?
A: The initial capacity determines the size of the underlying array. A larger capacity reduces the likelihood of collisions but increases memory consumption. A smaller capacity can lead to more frequent collisions and slower performance. It is generally recommended to choose an initial capacity that is slightly larger than the expected number of entries.
Q: What is the difference between HashMap and TreeMap?
A: While both HashMap and TreeMap implement the Map interface, they differ in their underlying data structures and ordering. HashMaps are unordered, while TreeMaps maintain a sorted order based on the keys. TreeMap offers efficient operations for sorted data, while HashMap excels in speed and flexibility.
Q: What is the load factor of a HashMap?
A: The load factor represents the threshold at which the HashMap automatically resizes. When the number of entries exceeds the load factor multiplied by the initial capacity, the HashMap undergoes resizing to maintain optimal performance. The default load factor is 0.75, which strikes a balance between efficiency and memory usage.
Tips for Effective HashMap Usage
- Choose appropriate initial capacity: Consider the expected number of entries to avoid excessive resizing and performance degradation.
- Use immutable keys: Immutable keys ensure that the hash code remains consistent, preventing unnecessary recalculations and potential performance issues.
- Understand the impact of collisions: While collisions are inevitable, excessive collisions can impact performance. Consider adjusting the initial capacity or load factor to mitigate this issue.
-
Utilize the
containsKey()method: Avoid unnecessary iterations by checking if a key exists before attempting to retrieve its value. -
Be aware of thread safety: HashMaps are not inherently thread-safe. For concurrent access, consider using the
ConcurrentHashMapclass or implementing synchronization mechanisms.
Conclusion
HashMaps in Java are a powerful and versatile data structure that plays a crucial role in various programming tasks. Their efficient lookup operations, dynamic sizing, and flexibility make them an invaluable tool for developers seeking to optimize performance and manage data effectively. By understanding the principles behind HashMaps and applying best practices, developers can leverage their capabilities to create robust and efficient applications.



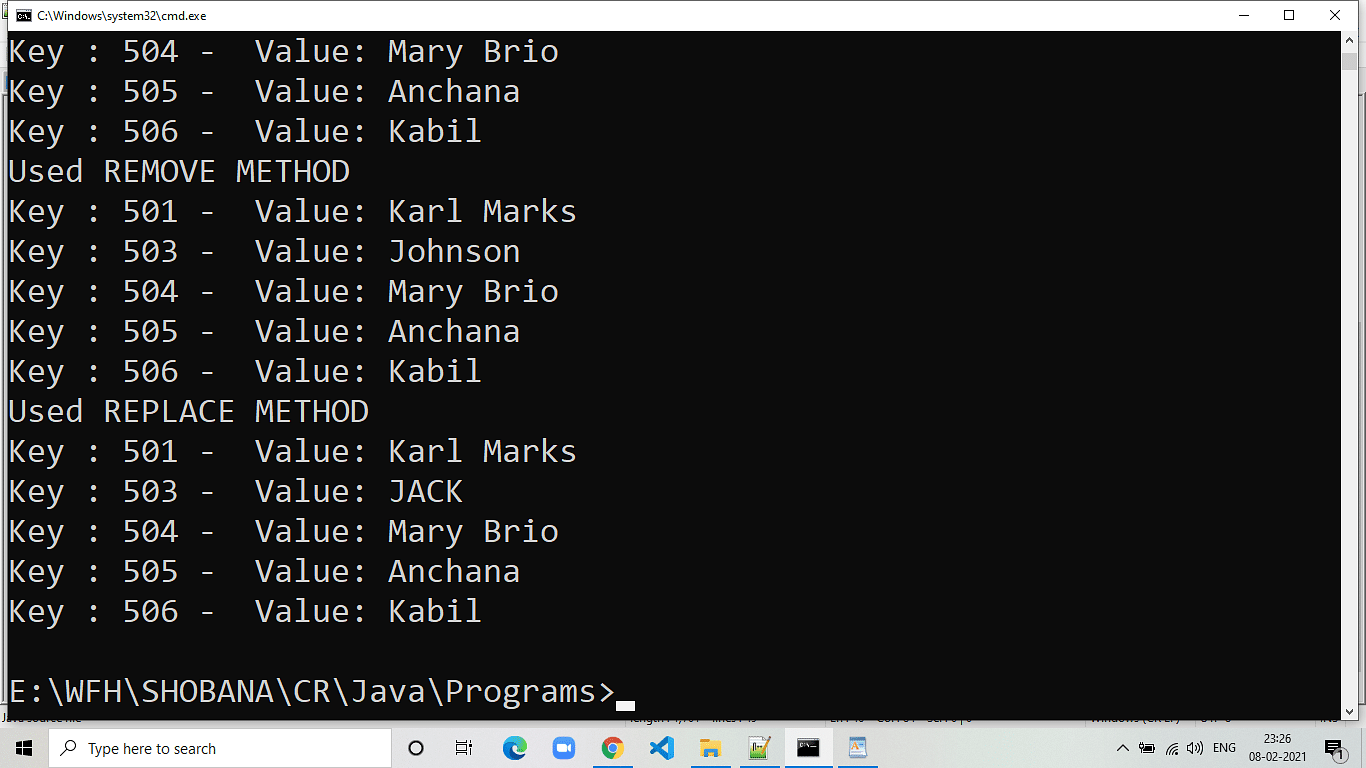
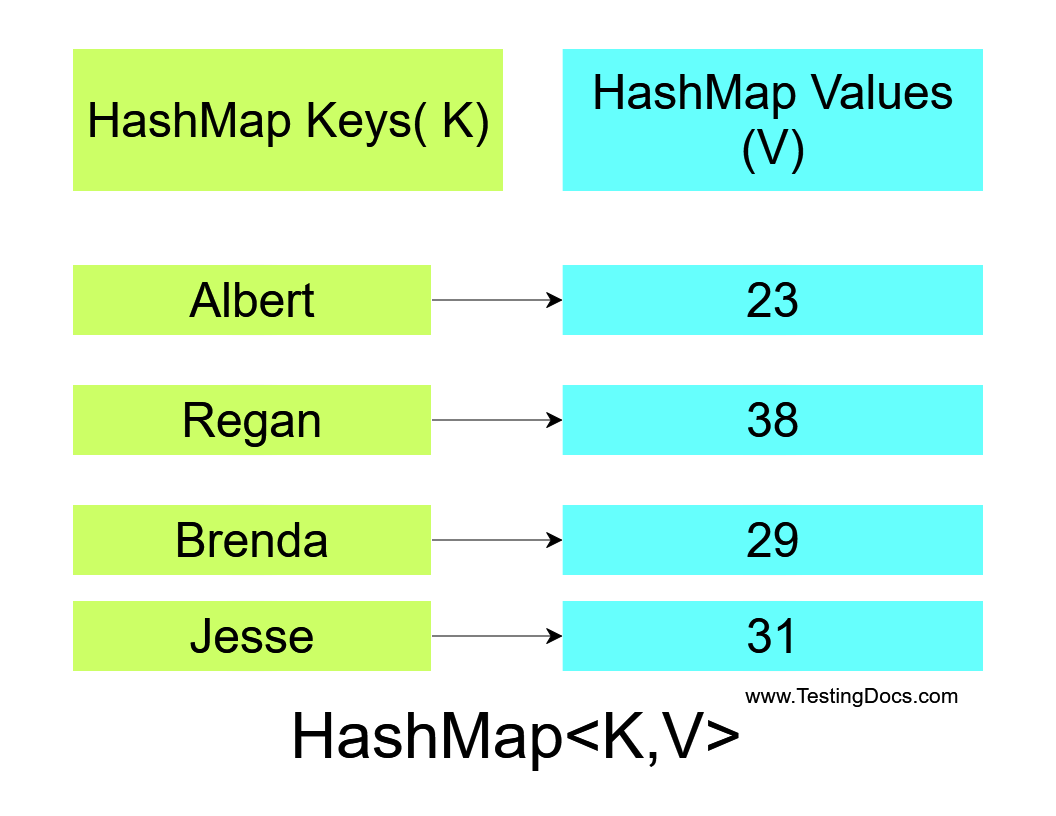
Closure
Thus, we hope this article has provided valuable insights into Unveiling the Efficiency of HashMaps in Java: A Comprehensive Guide. We appreciate your attention to our article. See you in our next article!