Unveiling Hidden Structures: A Comprehensive Guide To UMAP And HDBSCAN For Data Exploration And Analysis
Unveiling Hidden Structures: A Comprehensive Guide to UMAP and HDBSCAN for Data Exploration and Analysis
Related Articles: Unveiling Hidden Structures: A Comprehensive Guide to UMAP and HDBSCAN for Data Exploration and Analysis
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to Unveiling Hidden Structures: A Comprehensive Guide to UMAP and HDBSCAN for Data Exploration and Analysis. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Unveiling Hidden Structures: A Comprehensive Guide to UMAP and HDBSCAN for Data Exploration and Analysis
- 2 Introduction
- 3 Unveiling Hidden Structures: A Comprehensive Guide to UMAP and HDBSCAN for Data Exploration and Analysis
- 3.1 UMAP: Navigating the Labyrinth of High-Dimensional Data
- 3.2 HDBSCAN: Unveiling the True Clusters in Noisy Data
- 3.3 The Synergy of UMAP and HDBSCAN: A Powerful Combination
- 3.4 Frequently Asked Questions (FAQs)
- 3.5 Tips for Effective UMAP and HDBSCAN Implementation
- 3.6 Conclusion: Unlocking the Hidden Structure of Data
- 4 Closure
Unveiling Hidden Structures: A Comprehensive Guide to UMAP and HDBSCAN for Data Exploration and Analysis

In the realm of data science, understanding the underlying structure and relationships within complex datasets is paramount. This pursuit often involves the application of dimensionality reduction techniques and clustering algorithms, tools that effectively navigate the challenges posed by high-dimensional data. Two powerful and complementary techniques that have gained significant traction in recent years are Uniform Manifold Approximation and Projection (UMAP) and Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN).
This article delves into the intricacies of UMAP and HDBSCAN, providing a comprehensive understanding of their functionalities, strengths, and applications. By elucidating the theoretical underpinnings of these methods and showcasing their practical implementations, this exploration aims to equip readers with the knowledge necessary to effectively leverage these techniques for data exploration and analysis.
UMAP: Navigating the Labyrinth of High-Dimensional Data
UMAP stands as a robust and versatile dimensionality reduction technique, designed to preserve the intrinsic geometric structure of data while projecting it into a lower-dimensional space. Its effectiveness stems from its ability to capture both local and global relationships within the data, ensuring that the resulting embedding accurately reflects the original data’s inherent organization.
Theoretical Foundations:
UMAP’s core principle lies in the concept of a manifold, a geometric object that can be locally approximated by a Euclidean space. The assumption is that high-dimensional data often resides on a low-dimensional manifold embedded within the higher-dimensional space. UMAP aims to uncover this hidden manifold and project the data onto it, thereby reducing dimensionality while preserving the essential topological structure.
Key Components:
- Nearest Neighbor Search: UMAP begins by constructing a k-nearest neighbor graph for the data, capturing local relationships between data points.
- Fuzzy Simplicial Complex: This graph is then transformed into a fuzzy simplicial complex, representing the manifold’s structure through a network of connections between data points.
- Optimization Algorithm: The final step involves optimizing the embedding of the data in the lower-dimensional space, minimizing the divergence between the original and projected manifolds. This optimization process ensures that the global structure of the data is preserved.
Strengths of UMAP:
- Preservation of Global and Local Structure: UMAP excels at preserving both global and local relationships within the data, leading to accurate and meaningful low-dimensional representations.
- Speed and Efficiency: Compared to other dimensionality reduction techniques like t-SNE, UMAP offers significant speed advantages, making it suitable for large datasets.
- Versatility: UMAP can be applied to various data types, including continuous, categorical, and mixed data.
- Interpretability: The resulting low-dimensional embedding often provides insights into the underlying structure of the data, facilitating visualization and analysis.
Applications of UMAP:
UMAP finds applications in diverse fields, including:
- Data Visualization: UMAP enables the visualization of high-dimensional data, revealing patterns and clusters that might be obscured in the original space.
- Clustering: UMAP can be used as a preprocessing step for clustering algorithms, providing a more informative representation of the data for clustering.
- Anomaly Detection: By identifying outliers in the low-dimensional embedding, UMAP can assist in anomaly detection.
- Machine Learning: UMAP can be employed to improve the performance of machine learning models by providing more informative features.
HDBSCAN: Unveiling the True Clusters in Noisy Data
HDBSCAN emerges as a powerful clustering algorithm, capable of identifying clusters of varying densities and shapes within complex datasets. Unlike traditional clustering methods that rely on fixed-size clusters, HDBSCAN dynamically identifies clusters based on the density of data points, making it particularly well-suited for handling noisy and irregularly shaped clusters.
Theoretical Foundations:
HDBSCAN builds upon the concept of density-based clustering, where clusters are defined as regions of high density separated by regions of low density. The algorithm employs a hierarchical density estimation approach, constructing a hierarchy of clusters based on the density of data points at different scales.
Key Components:
- Density Estimation: HDBSCAN first estimates the density of data points using a k-nearest neighbor approach.
- Hierarchical Clustering: Based on the density estimates, a hierarchical clustering tree is constructed, representing the nesting of clusters at different density levels.
- Cluster Extraction: The final step involves extracting clusters from the hierarchical tree based on a stability criterion. This criterion considers the persistence of clusters across different density levels, ensuring the identification of robust clusters.
Strengths of HDBSCAN:
- Robustness to Noise: HDBSCAN effectively handles noisy data, identifying clusters even in the presence of outliers and irregular shapes.
- Variable Cluster Sizes: The algorithm can detect clusters of varying sizes and densities, accommodating the inherent diversity of real-world datasets.
- Intuitive Interpretation: The hierarchical clustering structure provides insights into the relationships between clusters at different density levels.
- Scalability: HDBSCAN can be applied to large datasets, making it suitable for real-world applications.
Applications of HDBSCAN:
HDBSCAN finds applications in diverse domains, including:
- Customer Segmentation: Identifying distinct customer groups based on their purchasing behavior or demographics.
- Image Segmentation: Grouping pixels into meaningful regions based on their color and texture characteristics.
- Anomaly Detection: Identifying outliers or unusual data points that do not belong to any cluster.
- Social Network Analysis: Detecting communities or groups of individuals with similar interests or connections.
The Synergy of UMAP and HDBSCAN: A Powerful Combination
UMAP and HDBSCAN complement each other seamlessly, forming a powerful combination for data exploration and analysis. UMAP serves as an effective dimensionality reduction technique, providing a more informative representation of the data for clustering. HDBSCAN then leverages this reduced representation to identify clusters of varying densities and shapes, revealing the underlying structure of the data.
Benefits of Combining UMAP and HDBSCAN:
- Improved Clustering Accuracy: UMAP’s ability to preserve the intrinsic geometry of the data enhances the accuracy of HDBSCAN’s clustering results.
- Visualization of Clusters: UMAP’s low-dimensional embedding facilitates the visualization of clusters identified by HDBSCAN, providing a clearer understanding of the data’s structure.
- Efficient Handling of Large Datasets: Combining UMAP’s speed and efficiency with HDBSCAN’s scalability allows for the analysis of large and complex datasets.
- Enhanced Interpretability: The combination of dimensionality reduction and clustering techniques provides a deeper understanding of the data’s underlying structure and relationships.
Frequently Asked Questions (FAQs)
1. What are the key differences between UMAP and t-SNE?
While both UMAP and t-SNE are dimensionality reduction techniques, they differ in their underlying principles and performance characteristics. t-SNE focuses primarily on preserving local relationships within the data, potentially sacrificing global structure. UMAP, on the other hand, aims to preserve both local and global relationships, resulting in more accurate and informative low-dimensional representations. Additionally, UMAP generally offers faster execution speeds than t-SNE, particularly for large datasets.
2. How do I choose the optimal parameters for UMAP and HDBSCAN?
Selecting the optimal parameters for UMAP and HDBSCAN involves a balance of exploration and evaluation. The choice of parameters like the number of neighbors (k) for UMAP and the minimum cluster size for HDBSCAN can significantly influence the results. Experimentation with different parameter values and evaluating the resulting embeddings and clusters using metrics like silhouette score or Davies-Bouldin index can guide the selection of optimal parameters.
3. Can UMAP and HDBSCAN be used for categorical data?
While UMAP is primarily designed for continuous data, it can be extended to handle categorical data through various techniques. One approach involves encoding categorical variables into numerical representations, such as one-hot encoding. HDBSCAN, on the other hand, can directly handle categorical data, as it relies on density estimations based on distances between data points, which can be calculated for both continuous and categorical variables.
4. What are the limitations of UMAP and HDBSCAN?
Despite their strengths, UMAP and HDBSCAN have limitations that should be considered. UMAP’s performance can be affected by the presence of noise or outliers in the data. HDBSCAN’s reliance on density estimation can lead to challenges in identifying clusters with varying densities or non-convex shapes. Additionally, both methods can be computationally expensive for extremely large datasets.
Tips for Effective UMAP and HDBSCAN Implementation
- Preprocessing: Before applying UMAP or HDBSCAN, it is essential to preprocess the data appropriately. This includes handling missing values, scaling variables, and addressing outliers.
- Parameter Tuning: Experiment with different parameter values for UMAP and HDBSCAN to find the optimal settings for your specific dataset.
- Visualization: Visualizing the low-dimensional embeddings generated by UMAP and the clusters identified by HDBSCAN can provide valuable insights into the data’s structure.
- Evaluation Metrics: Employ appropriate evaluation metrics to assess the quality of the embeddings and clusters, ensuring that the results are meaningful and informative.
- Domain Knowledge: Incorporate domain knowledge into the analysis, using it to interpret the results and validate the findings.
Conclusion: Unlocking the Hidden Structure of Data
UMAP and HDBSCAN stand as powerful tools for data exploration and analysis, offering a unique combination of dimensionality reduction and clustering capabilities. By effectively reducing dimensionality and identifying clusters of varying densities and shapes, these techniques enable the discovery of hidden structures within complex datasets. Their versatility, robustness, and efficiency make them invaluable assets for researchers and practitioners across various domains. As data continues to grow in size and complexity, the importance of techniques like UMAP and HDBSCAN will only continue to rise, empowering us to navigate the labyrinth of high-dimensional data and unlock its hidden insights.

![[译]理解 UMAP(1):UMAP是如何工作的 & UMAP 与 tSNE的原理对比 - 知乎](https://pic3.zhimg.com/v2-99c896ead0b588ad897a9fb786af843a_b.png)



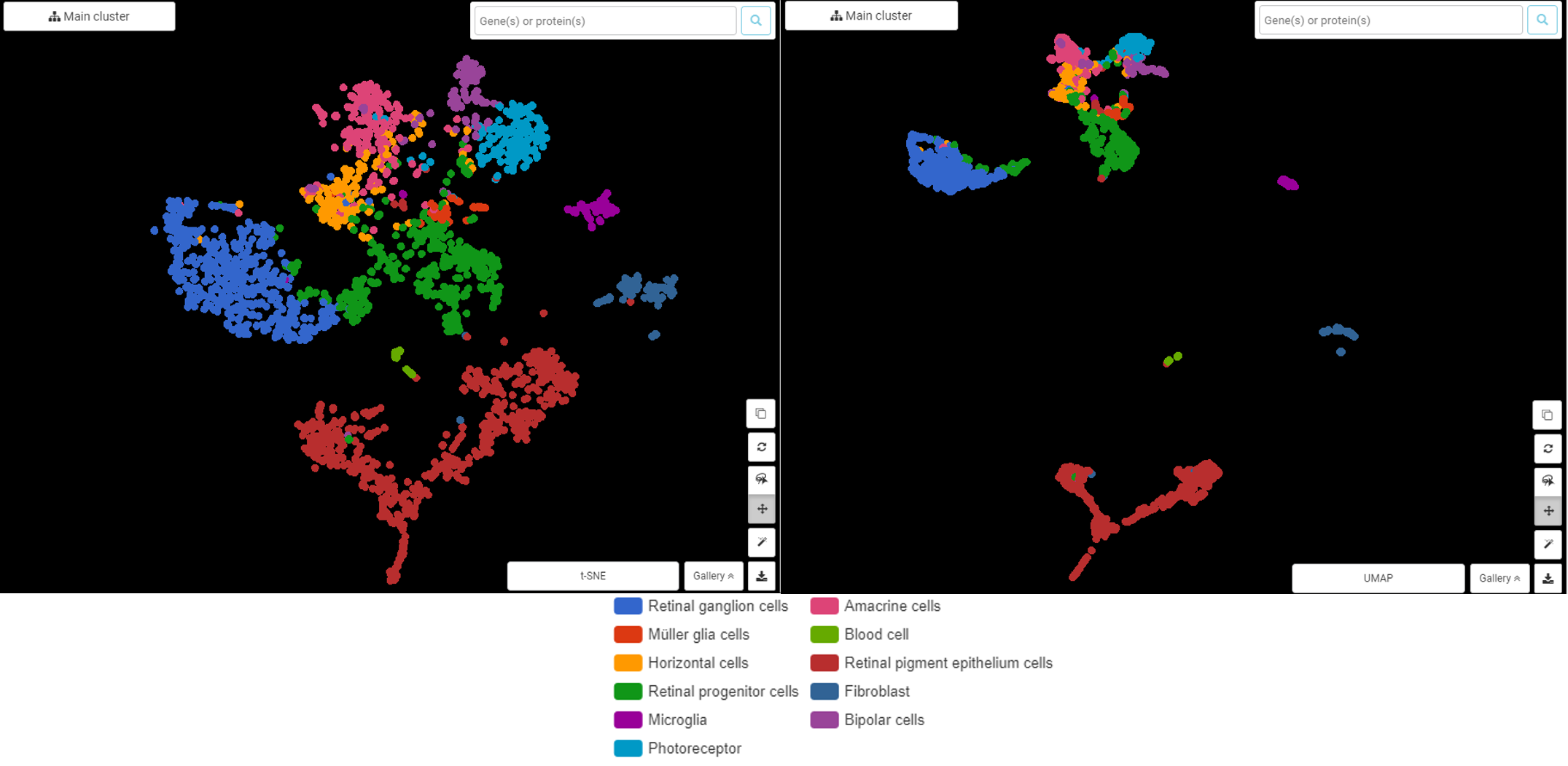


Closure
Thus, we hope this article has provided valuable insights into Unveiling Hidden Structures: A Comprehensive Guide to UMAP and HDBSCAN for Data Exploration and Analysis. We thank you for taking the time to read this article. See you in our next article!