Understanding Map And FlatMap In Spark: Transforming Data With Power And Efficiency
Understanding Map and FlatMap in Spark: Transforming Data with Power and Efficiency
Related Articles: Understanding Map and FlatMap in Spark: Transforming Data with Power and Efficiency
Introduction
In this auspicious occasion, we are delighted to delve into the intriguing topic related to Understanding Map and FlatMap in Spark: Transforming Data with Power and Efficiency. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Understanding Map and FlatMap in Spark: Transforming Data with Power and Efficiency
- 2 Introduction
- 3 Understanding Map and FlatMap in Spark: Transforming Data with Power and Efficiency
- 3.1 Map: Applying Functions to Each Element
- 3.2 FlatMap: Expanding and Flattening Data
- 3.3 The Power of Map and FlatMap: Practical Applications
- 3.4 FAQs: Demystifying Map and FlatMap
- 3.5 Tips for Effective Use of Map and FlatMap
- 3.6 Conclusion: The Cornerstones of Spark Data Manipulation
- 4 Closure
Understanding Map and FlatMap in Spark: Transforming Data with Power and Efficiency

Apache Spark, a powerful distributed computing framework, empowers developers to process vast datasets with unparalleled speed and efficiency. Key to this power are the transformations map and flatMap, which allow for flexible and scalable data manipulation. This article delves into the intricacies of these transformations, highlighting their capabilities and applications within the Spark ecosystem.
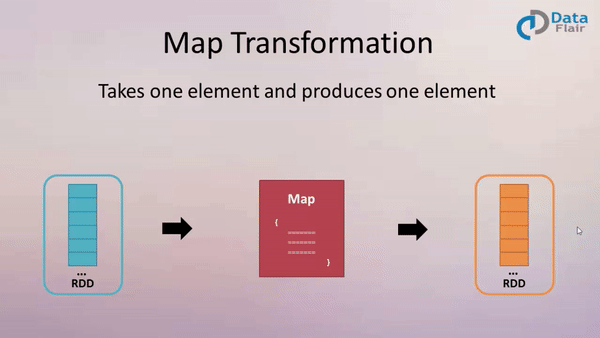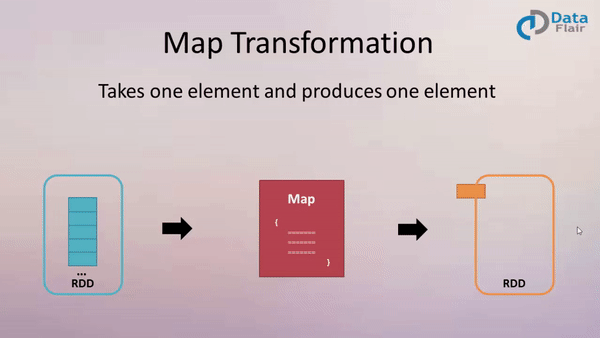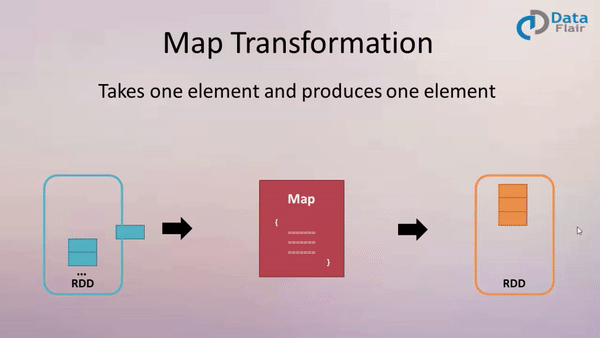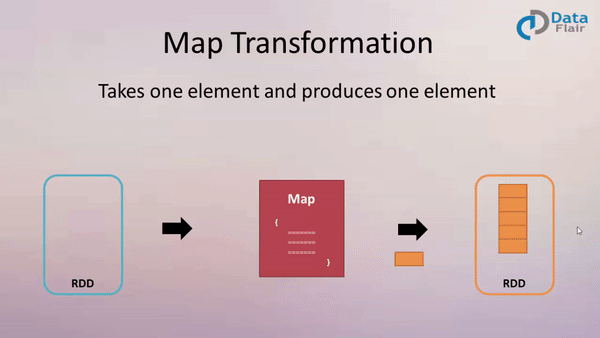
Map: Applying Functions to Each Element
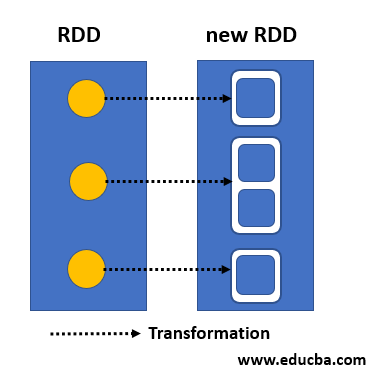
The map transformation in Spark operates on a distributed collection of data, known as an RDD (Resilient Distributed Dataset). It applies a user-defined function to each individual element in the RDD, producing a new RDD with the transformed elements.
Imagine a scenario where you have an RDD containing a list of names. You want to transform this RDD into one containing the lengths of each name. The map transformation provides the perfect solution. By applying a function that calculates the length of each string, you can efficiently generate a new RDD containing the lengths.
Example:
names = sc.parallelize(["Alice", "Bob", "Charlie", "David"])
nameLengths = names.map(lambda name: len(name))
print(nameLengths.collect())This code snippet creates an RDD named names containing the names. The map transformation applies the lambda function len(name) to each element, calculating the length of each name. The resulting RDD, nameLengths, contains the lengths of the names: [5, 3, 8, 5].
Key Features of Map:
- One-to-one transformation: Each element in the input RDD maps to exactly one element in the output RDD.
- Preserves order: The order of elements is maintained in the output RDD, reflecting the order in the input RDD.
- Efficiency: Spark distributes the mapping operation across multiple executors, leveraging parallelism for optimal performance.
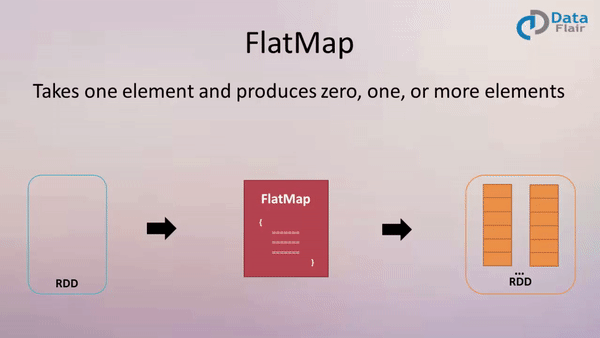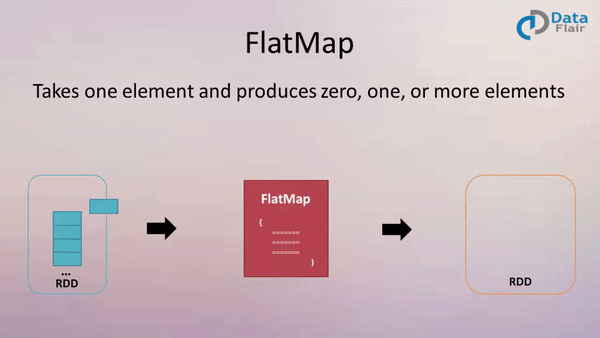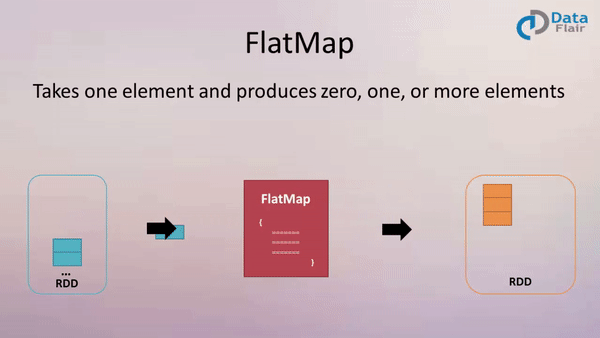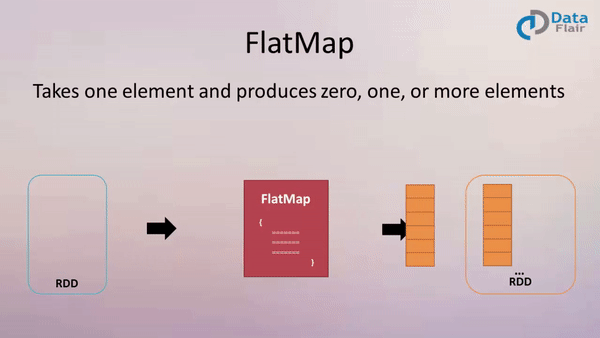
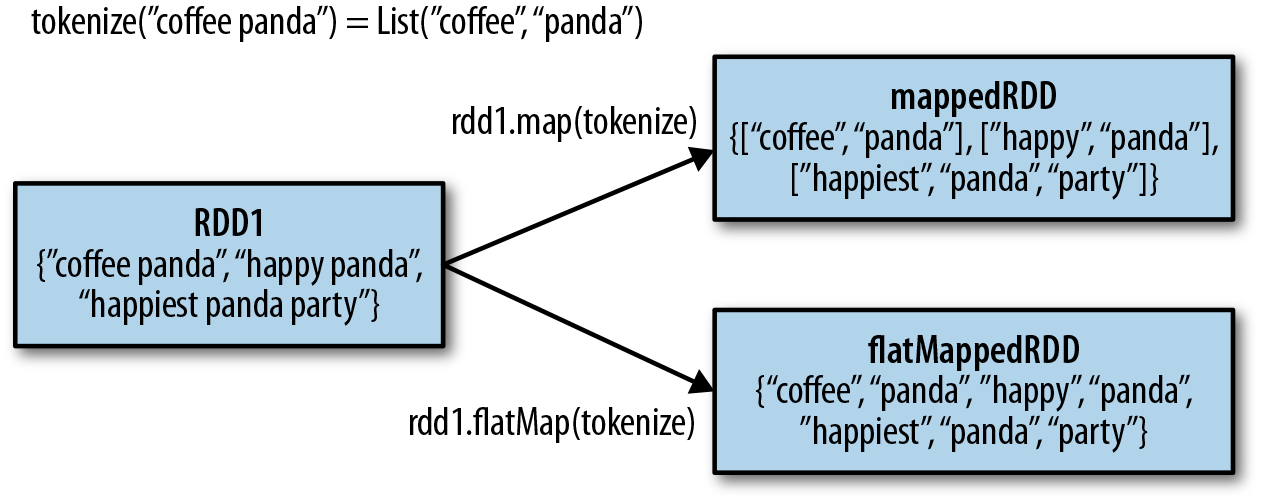
FlatMap: Expanding and Flattening Data
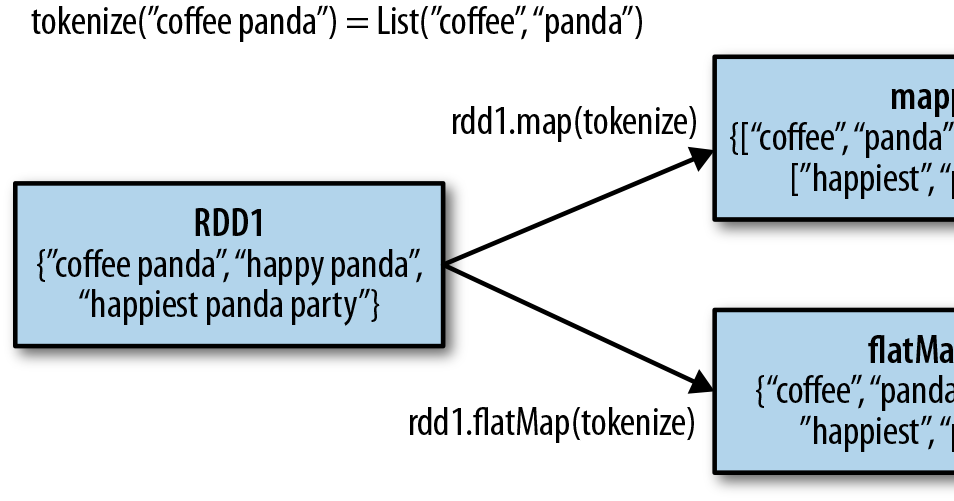
The flatMap transformation extends the functionality of map by allowing for the generation of multiple elements from a single input element. This transformation applies a function to each element, which can return an iterable (e.g., list, tuple) containing multiple elements. The resulting RDD is then flattened, combining all the elements from the iterables into a single, flat RDD.
Consider an RDD containing sentences. You might want to extract individual words from each sentence, resulting in an RDD containing all the words. The flatMap transformation enables this by applying a function that splits each sentence into words, generating a list of words for each sentence. The resulting RDD is then flattened, containing all the individual words.
Example:
sentences = sc.parallelize(["This is a sentence.", "Another sentence here."])
words = sentences.flatMap(lambda sentence: sentence.split())
print(words.collect())This code snippet creates an RDD named sentences containing two sentences. The flatMap transformation applies the lambda function sentence.split() to each sentence, splitting it into individual words. The resulting RDD, words, contains all the words from the sentences: ['This', 'is', 'a', 'sentence.', 'Another', 'sentence', 'here.'].
Key Features of FlatMap:
- One-to-many transformation: Each element in the input RDD can map to zero, one, or multiple elements in the output RDD.
- Flattening: Elements from the iterables generated by the applied function are flattened into a single, flat RDD.
- Flexibility: FlatMap allows for complex data transformations, enabling the creation of new RDDs with different structures and content.
The Power of Map and FlatMap: Practical Applications
The map and flatMap transformations are fundamental building blocks in Spark’s data processing pipeline. Their versatility enables a wide range of data manipulation tasks, including:
- Data Cleaning and Preprocessing: Removing unwanted characters, converting data types, and handling missing values can be achieved efficiently using map and flatMap.
- Data Transformation: Applying mathematical operations, converting data formats, and extracting specific fields are common data transformations facilitated by these transformations.
- Feature Engineering: Creating new features from existing data, such as combining multiple columns, calculating ratios, or generating statistical summaries, can be performed using map and flatMap.
- Data Aggregation: Grouping data based on specific criteria and performing aggregations like sum, average, or count can be achieved using these transformations in conjunction with other Spark operations like reduceByKey.
- Text Processing: Tasks like word counting, tokenization, and stemming are made easier with the use of flatMap to extract individual words from text data.
FAQs: Demystifying Map and FlatMap
Q: What is the difference between map and flatMap?
A: map applies a function to each element, producing one output element for each input element. flatMap also applies a function but allows the function to return multiple elements, which are then flattened into a single RDD.
Q: Can I use map and flatMap together in a single Spark program?
A: Absolutely! map and flatMap can be chained together to perform complex data transformations. For example, you could use flatMap to split sentences into words, then map to convert each word to lowercase.
Q: How do I choose between map and flatMap?
A: If you need to apply a function that produces one output element per input element, use map. If you need to generate multiple elements from a single input element, use flatMap.
Q: Is there a performance difference between map and flatMap?
A: Generally, map is slightly faster than flatMap due to its simpler operation. However, the performance difference is often negligible, especially when dealing with large datasets.
Q: Can I use map and flatMap with other Spark transformations?
A: Yes, map and flatMap can be combined with other Spark transformations like filter, reduceByKey, and join to create powerful and efficient data processing pipelines.
Tips for Effective Use of Map and FlatMap
- Choose the right transformation: Carefully consider whether map or flatMap is the appropriate choice for your specific data transformation.
- Optimize function performance: Ensure the function applied in map or flatMap is efficient and optimized for performance.
- Leverage parallelism: Spark’s distributed nature allows for parallel execution of map and flatMap. Ensure your data is partitioned appropriately for optimal performance.
- Use chaining for complex operations: Combine map and flatMap with other Spark transformations to create complex data processing pipelines.
- Test and analyze performance: Measure the performance of your map and flatMap operations to identify potential bottlenecks and optimize for efficiency.
Conclusion: The Cornerstones of Spark Data Manipulation
The map and flatMap transformations are essential tools in the Spark developer’s arsenal. Their ability to apply functions to RDD elements, producing new RDDs with transformed data, is fundamental to data processing tasks. By understanding their capabilities and applying them effectively, developers can leverage the power of Spark to manipulate large datasets with speed, efficiency, and flexibility. Mastering these transformations unlocks a world of possibilities, empowering developers to extract meaningful insights from vast amounts of data.


Closure
Thus, we hope this article has provided valuable insights into Understanding Map and FlatMap in Spark: Transforming Data with Power and Efficiency. We hope you find this article informative and beneficial. See you in our next article!